Part of Putting the “You” in CPU: a rabbit hole into how your computer runs programs.
Chapter 1: The “Basics” Edit on GitHub
The one thing that surprised me over and over again while writing this article was how simple computers are. It’s still hard for me not to psych myself out, expecting more complexity or abstraction than actually exists! If there’s one thing you should burn into your brain before continuing, it’s that everything that seems simple actually is that simple. This simplicity is very beautiful and sometimes very, very cursed.
Let’s start with the basics of how your computer works at its very core.
How Computers Are Architected
The central processing unit (CPU) of a computer is in charge of all computation. It’s the big cheese. The shazam alakablam. It starts chugging as soon as you start your computer, executing instruction after instruction after instruction.
The first mass-produced CPU was the Intel 4004, designed in the late 60s by an Italian physicist and engineer named Federico Faggin. It was a 4-bit architecture instead of the 64-bit systems we use today, and it was far less complex than modern processors, but a lot of its simplicity does still remain.
The “instructions” that CPUs execute are just binary data: a byte or two to represent what instruction is being run (the opcode), followed by whatever data is needed to run the instruction. What we call machine code is nothing but a series of these binary instructions in a row. Assembly is a helpful syntax for reading and writing machine code that’s easier for humans to read and write than raw bits; it is always compiled to the binary that your CPU knows how to read.

An aside: instructions aren’t always represented 1:1 in machine code as in the above example. For example,
add eax, 512translates to05 00 02 00 00.The first byte (
05) is an opcode specifically representing adding the EAX register to a 32-bit number. The remaining bytes are 512 (0x200) in little-endian byte order.Defuse Security created a helpful tool for playing around with the translation between assembly and machine code.
RAM is your computer’s main memory bank, a large multi-purpose space which stores all the data used by programs running on your computer. That includes the program code itself as well as the code at the core of the operating system. The CPU always reads machine code directly from RAM, and code can’t be run if it isn’t loaded into RAM.
The CPU stores an instruction pointer which points to the location in RAM where it’s going to fetch the next instruction. After executing each instruction, the CPU moves the pointer and repeats. This is the fetch-execute cycle.
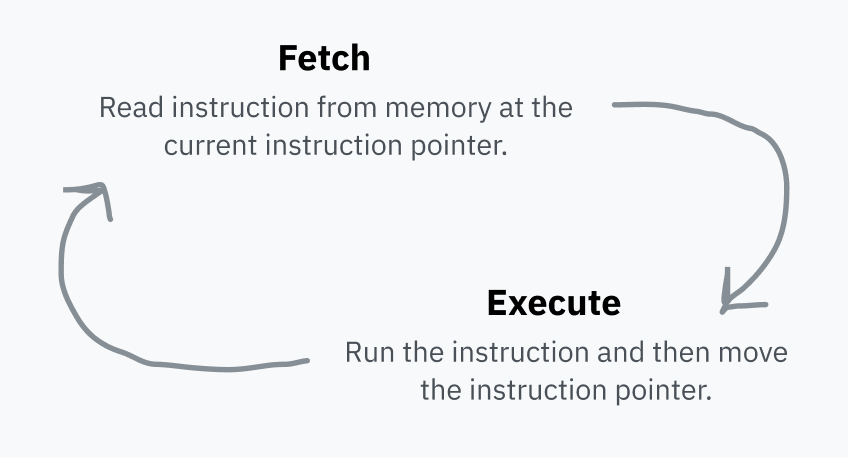
After executing an instruction, the pointer moves forward to immediately after the instruction in RAM so that it now points to the next instruction. That’s why code runs! The instruction pointer just keeps chugging forward, executing machine code in the order in which it has been stored in memory. Some instructions can tell the instruction pointer to jump somewhere else instead, or jump different places depending on a certain condition; this makes reusable code and conditional logic possible.
This instruction pointer is stored in a register. Registers are small storage buckets that are extremely fast for the CPU to read and write to. Each CPU architecture has a fixed set of registers, used for everything from storing temporary values during computations to configuring the processor.
Some registers are directly accessible from machine code, like ebx in the earlier diagram.
Other registers are only used internally by the CPU, but can often be updated or read using specialized instructions. One example is the instruction pointer, which can’t be read directly but can be updated with, for example, a jump instruction.
Processors Are Naive
Let’s go back to the original question: what happens when you run an executable program on your computer? First, a bunch of magic happens to get ready to run it — we’ll work through all of this later — but at the end of the process there’s machine code in a file somewhere. The operating system loads this into RAM and instructs the CPU to jump the instruction pointer to that position in RAM. The CPU continues running its fetch-execute cycle as usual, so the program begins executing!
(This was one of those psyching-myself-out moments for me — seriously, this is how the program you are using to read this article is running! Your CPU is fetching your browser’s instructions from RAM in sequence and directly executing them, and they’re rendering this article.)
It turns out CPUs have a super basic worldview; they only see the current instruction pointer and a bit of internal state. Processes are entirely operating system abstractions, not something CPUs natively understand or keep track of.
*waves hands* processes are abstractions made up by os devs big byte to sell more computers
For me, this raises more questions than it answers:
- If the CPU doesn’t know about multiprocessing and just executes instructions sequentially, why doesn’t it get stuck inside whatever program it’s running? How can multiple programs run at once?
- If programs run directly on the CPU, and the CPU can directly access RAM, why can’t code access memory from other processes, or, god forbid, the kernel?
- Speaking of which, what’s the mechanism that prevents every process from running any instruction and doing anything to your computer? AND WHAT’S A DAMN SYSCALL?
The question about memory deserves its own section and is covered in chapter 5 — the TL;DR is that most memory accesses actually go through a layer of misdirection that remaps the entire address space. For now, we’re going to pretend that programs can access all RAM directly and computers can only run one process at once. We’ll explain away both of these assumptions in time.
It’s time to leap through our first rabbit hole into a land filled with syscalls and security rings.
Aside: what is a kernel, btw?
Your computer’s operating system, like macOS, Windows, or Linux, is the collection of software that runs on your computer and makes all the basic stuff work. “Basic stuff” is a really general term, and so is “operating system” — depending on who you ask, it can include such things as the apps, fonts, and icons that come with your computer by default.
The kernel, however, is the core of the operating system. When you boot up your computer, the instruction pointer starts at a program somewhere. That program is the kernel. The kernel has near-full access to your computer’s memory, peripherals, and other resources, and is in charge of running software installed on your computer (known as userland programs). We’ll learn about how the kernel has this access — and how userland programs don’t — over the course of this article.
Linux is just a kernel and needs plenty of userland software like shells and display servers to be usable. The kernel in macOS is called XNU and is Unix-like, and the modern Windows kernel is called the NT Kernel.
Two Rings to Rule Them All
The mode (sometimes called privilege level or ring) a processor is in controls what it’s allowed to do. Modern architectures have at least two options: kernel/supervisor mode and user mode. While an architecture might support more than two modes, only kernel mode and user mode are commonly used these days.
In kernel mode, anything goes: the CPU is allowed to execute any supported instruction and access any memory. In user mode, only a subset of instructions is allowed, I/O and memory access is limited, and many CPU settings are locked. Generally, the kernel and drivers run in kernel mode while applications run in user mode.
Processors start in kernel mode. Before executing a program, the kernel initiates the switch to user mode.

An example of how processor modes manifest in a real architecture: on x86-64, the current privilege level (CPL) can be read from a register called cs (code segment). Specifically, the CPL is contained in the two least significant bits of the cs register. Those two bits can store x86-64’s four possible rings: ring 0 is kernel mode and ring 3 is user mode. Rings 1 and 2 are designed for running drivers but are only used by a handful of older niche operating systems. If the CPL bits are 11, for example, the CPU is running in ring 3: user mode.
What Even is a Syscall?
Programs run in user mode because they can’t be trusted with full access to the computer. User mode does its job, preventing access to most of the computer — but programs need to be able to access I/O, allocate memory, and interact with the operating system somehow! To do so, software running in user mode has to ask the operating system kernel for help. The OS can then implement its own security protections to prevent programs from doing anything malicious.
If you’ve ever written code that interacts with the OS, you’ll probably recognize functions like open, read, fork, and exit. Below a couple of layers of abstraction, these functions all use system calls to ask the OS for help. A system call is a special procedure that lets a program start a transition from user space to kernel space, jumping from the program’s code into OS code.
User space to kernel space control transfers are accomplished using a processor feature called software interrupts:
- During the boot process, the operating system stores a table called an interrupt vector table (IVT; x86-64 calls this the interrupt descriptor table) in RAM and registers it with the CPU. The IVT maps interrupt numbers to handler code pointers.

- Then, userland programs can use an instruction like INT which tells the processor to look up the given interrupt number in the IVT, switch to kernel mode, and then jump the instruction pointer to the memory address stored in the IVT.
When this kernel code finishes, it uses an instruction like IRET to tell the CPU to switch back to user mode and return the instruction pointer to where it was when the interrupt was triggered.
(If you were curious, the interrupt ID used for system calls on Linux is 0x80. You can read a list of Linux system calls on Michael Kerrisk’s online manpage directory.)
Wrapper APIs: Abstracting Away Interrupts
Here’s what we know so far about system calls:
- User mode programs can’t access I/O or memory directly. They have to ask the OS for help interacting with the outside world.
- Programs can delegate control to the OS with special machine code instructions like INT and IRET.
- Programs can’t directly switch privilege levels; software interrupts are safe because the processor has been preconfigured by the OS with where in the OS code to jump to. The interrupt vector table can only be configured from kernel mode.
Programs need to pass data to the operating system when triggering a syscall; the OS needs to know which specific system call to execute alongside any data the syscall itself needs, for example, what filename to open. The mechanism for passing this data varies by operating system and architecture, but it’s usually done by placing data in certain registers or on the stack before triggering the interrupt.
The variance in how system calls are called across devices means it would be wildly impractical for programmers to implement system calls themselves for every program. This would also mean operating systems couldn’t change their interrupt handling for fear of breaking every program that was written to use the old system. Finally, we typically don’t write programs in raw assembly anymore — programmers can’t be expected to drop down to assembly any time they want to read a file or allocate memory.
So, operating systems provide an abstraction layer on top of these interrupts. Reusable higher-level library functions that wrap the necessary assembly instructions are provided by libc on Unix-like systems and part of a library called ntdll.dll on Windows. Calls to these library functions themselves don’t cause switches to kernel mode, they’re just standard function calls. Inside the libraries, assembly code does actually transfer control to the kernel, and is a lot more platform-dependent than the wrapping library subroutine.
When you call exit(1) from C running on a Unix-like system, that function is internally running machine code to trigger an interrupt, after placing the system call’s opcode and arguments in the right registers/stack/whatever. Computers are so cool!
The Need for Speed / Let’s Get CISC-y
Many CISC architectures like x86-64 contain instructions designed for system calls, created due to the prevalence of the system call paradigm.
Intel and AMD managed not to coordinate very well on x86-64; it actually has two sets of optimized system call instructions. SYSCALL and SYSENTER are optimized alternatives to instructions like INT 0x80. Their corresponding return instructions, SYSRET and SYSEXIT, are designed to transition quickly back to user space and resume program code.
(AMD and Intel processors have slightly different compatibility with these instructions. SYSCALL is generally the best option for 64-bit programs, while SYSENTER has better support with 32-bit programs.)
Representative of the style, RISC architectures tend not to have such special instructions. AArch64, the RISC architecture Apple Silicon is based on, uses only one interrupt instruction for syscalls and software interrupts alike. I think Mac users are doing fine :)
Whew, that was a lot! Let’s do a brief recap:
- Processors execute instructions in an infinite fetch-execute loop and don’t have any concept of operating systems or programs. The processor’s mode, usually stored in a register, determines what instructions may be executed. Operating system code runs in kernel mode and switches to user mode to run programs.
- To run a binary, the operating system switches to user mode and points the processor to the code’s entry point in RAM. Because they only have the privileges of user mode, programs that want to interact with the world need to jump to OS code for help. System calls are a standardized way for programs to switch from user mode to kernel mode and into OS code.
- Programs typically use these syscalls by calling shared library functions. These wrap machine code for either software interrupts or architecture-specific syscall instructions that transfer control to the OS kernel and switch rings. The kernel does its business and switches back to user mode and returns to the program code.
Let’s figure out how to answer my first question from earlier:
If the CPU doesn’t keep track of more than one process and just executes instruction after instruction, why doesn’t it get stuck inside whatever program it’s running? How can multiple programs run at once?
The answer to this, my dear friend, is also the answer to why Coldplay is so popular… clocks! (Well, technically timers. I just wanted to shoehorn that joke in.)
Continue to Chapter 2: Slice Dat Time